第 10 章 Permission Mode 与安全设计哲学
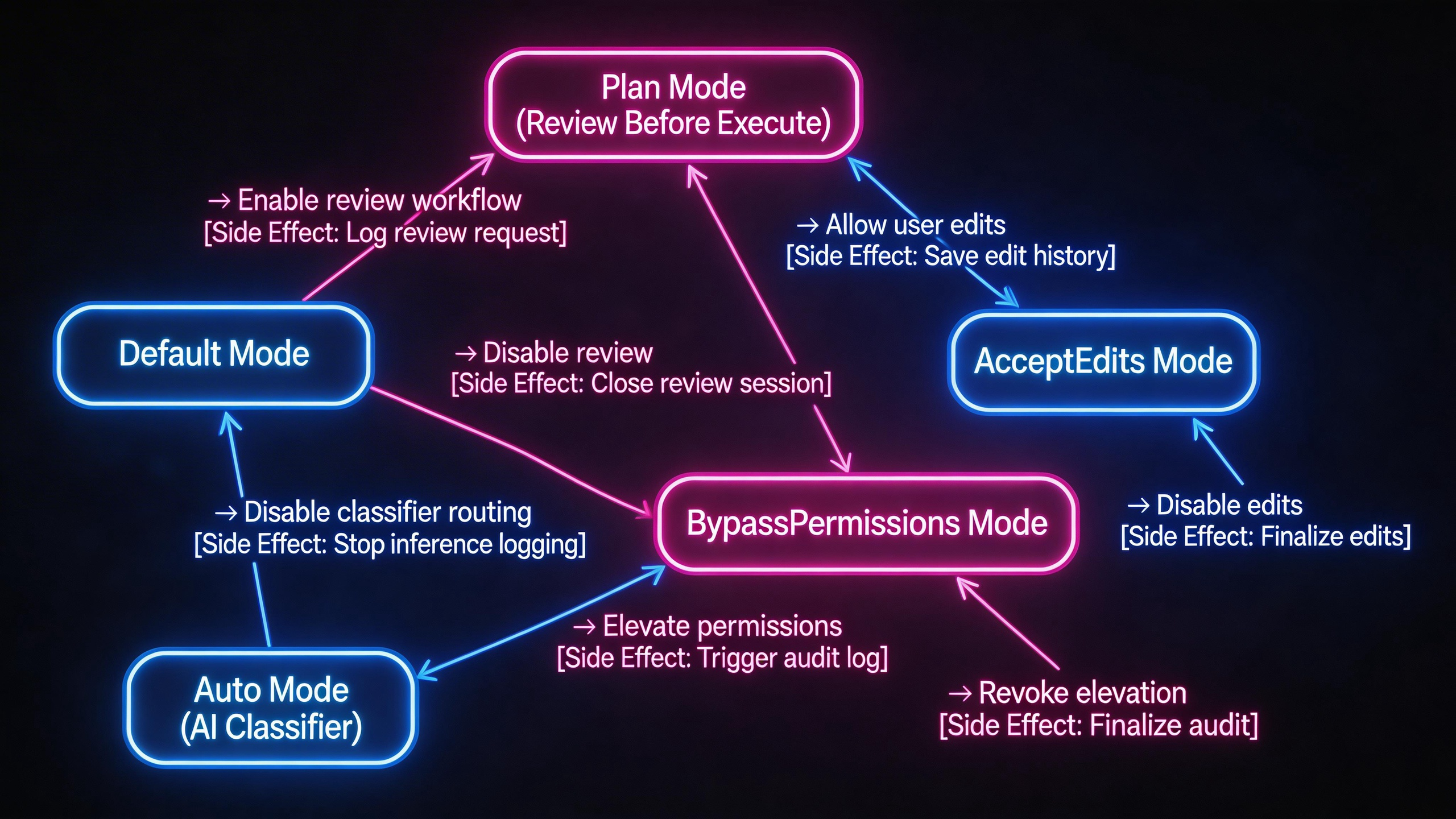
10.1 五种 Permission Mode 的设计思路
上一章我们剖析了 Claude Code 的四层权限架构——从配置规则到分类器,从交互审批到兜底拒绝,每一层都在做"这个操作能不能放行"的判断。但还有一个关键维度我们尚未触及:用户想要多大程度的自主性?
不同场景下,用户对 Agent 的信任边界截然不同。探索一个新代码库时,你可能希望 Claude 每执行一条 Shell 命令都先问你一声;而在一个已经写好 Plan 的重构任务中,你更希望它安静地把活干完。Permission Mode 正是 Claude Code 为这种差异化需求设计的"档位系统"。
在 src/types/permissions.ts 中,我们可以看到所有模式的完整定义:
export const EXTERNAL_PERMISSION_MODES = [
'acceptEdits',
'bypassPermissions',
'default',
'dontAsk',
'plan',
] as const
export type InternalPermissionMode = ExternalPermissionMode | 'auto' | 'bubble'面向外部用户的有五种模式,加上内部保留的 auto 和 bubble,一共七种。但核心设计围绕五种展开:
| 模式 | 含义 | 适用场景 |
|---|---|---|
default | 每个敏感操作都需要用户审批 | 日常使用、探索新项目 |
plan | 只读探索,不允许写操作 | 复杂任务的规划阶段 |
acceptEdits | 文件编辑自动通过,Shell 命令仍需审批 | 已确认方向的编码阶段 |
bypassPermissions | 跳过所有权限检查 | 完全信任 Agent 的场景 |
auto | AI 分类器自动判断命令安全性 | 需要高效但保留安全网的场景 |
在 src/utils/permissions/PermissionMode.ts 中,每种模式都被赋予了视觉标识:
const PERMISSION_MODE_CONFIG = {
default: { title: 'Default', symbol: '', color: 'text' },
plan: { title: 'Plan Mode', symbol: PAUSE_ICON, color: 'planMode' },
acceptEdits: { title: 'Accept edits', symbol: '⏵⏵', color: 'autoAccept' },
bypassPermissions: { title: 'Bypass Permissions', symbol: '⏵⏵', color: 'error' },
auto: { title: 'Auto mode', symbol: '⏵⏵', color: 'warning' },
}注意 bypassPermissions 用了 error 红色,而 auto 用了 warning 黄色——视觉上就在提醒用户:放开权限是有风险的,颜色越红越危险。
用户通过 Shift+Tab 快捷键在模式间循环切换。切换顺序在 src/utils/permissions/getNextPermissionMode.ts 中定义:
default → acceptEdits → plan → bypassPermissions → auto → default这个顺序不是随意排列的:从最保守的 default 开始,逐步放开到 acceptEdits,然后是只读的 plan,再到完全绕过的 bypassPermissions,最后是智能的 auto。每按一次 Shift+Tab,用户就在信任光谱上移动一格。
10.2 Plan Mode:先审阅,再执行
10.2.1 进入 Plan Mode
Plan Mode 是一个非常独特的设计——它不是放开权限,而是收紧权限。当 Agent 面对复杂任务时,Plan Mode 强制它进入"只读"阶段:只能搜索、阅读代码、分析架构,不能写入任何文件。
在 src/tools/EnterPlanModeTool/EnterPlanModeTool.ts 中,进入 Plan Mode 的逻辑非常清晰:
async call(_input, context) {
if (context.agentId) {
throw new Error('EnterPlanMode tool cannot be used in agent contexts')
}
const appState = context.getAppState()
handlePlanModeTransition(appState.toolPermissionContext.mode, 'plan')
context.setAppState(prev => ({
...prev,
toolPermissionContext: applyPermissionUpdate(
prepareContextForPlanMode(prev.toolPermissionContext),
{ type: 'setMode', mode: 'plan', destination: 'session' },
),
}))
return {
data: {
message: 'Entered plan mode. You should now focus on exploring the codebase and designing an implementation approach.',
},
}
}几个值得注意的设计决策:
- 子 Agent 不能进入 Plan Mode:
if (context.agentId) throw——Plan Mode 需要用户交互来审批计划,子 Agent 没有这个能力。 prepareContextForPlanMode:这个函数不仅仅切换模式,还会保存当前模式到prePlanMode字段,以便退出时恢复。如果当前是auto模式,它还会激活分类器,让 Plan Mode 下的读操作也享受自动审批。- 模式切换存储在
session级别:不会持久化到配置文件,重启后自动回到默认模式。
10.2.2 Plan Mode 的提示工程
src/tools/EnterPlanModeTool/prompt.ts 中对何时使用 Plan Mode 有精细的指导。面向外部用户,Claude 被告知倾向于使用 Plan Mode——新功能、多种方案、多文件变更、需求不清晰时都应该先规划:
"If unsure whether to use it, err on the side of planning — it's better to get alignment upfront than to redo work."
而面向内部用户(Anthropic 员工),指导更加宽松——只在真正存在架构歧义时才进入:
"When in doubt, prefer starting work and using AskUserQuestion for specific questions over entering a full planning phase."
这种分层的提示策略体现了一个务实的考量:外部用户更看重代码安全和方案确认,内部用户更看重开发效率。
10.2.3 退出 Plan Mode
退出 Plan Mode 通过 ExitPlanModeV2Tool 实现(src/tools/ExitPlanModeTool/ExitPlanModeV2Tool.ts)。这是一个需要用户交互的工具——Claude 写完计划后调用它,弹出审批弹窗,用户可以:
- 直接批准计划
- 编辑计划后批准
- 拒绝计划
退出时的模式恢复逻辑相当精密:
context.setAppState(prev => {
let restoreMode = prev.toolPermissionContext.prePlanMode ?? 'default'
if (feature('TRANSCRIPT_CLASSIFIER')) {
if (restoreMode === 'auto' && !isAutoModeGateEnabled()) {
restoreMode = 'default' // 熔断器生效,回退到 default
}
autoModeStateModule?.setAutoModeActive(restoreMode === 'auto')
}
// ...
})如果进入 Plan Mode 前是 auto 模式,退出时会尝试恢复到 auto。但如果期间熔断器触发了(isAutoModeGateEnabled 返回 false),就会安全地回退到 default——这种防御性设计贯穿整个系统。
10.3 推测执行(Speculation):在等待中抢跑
10.3.1 核心思想
推测执行是 Claude Code 中最巧妙的性能优化之一。它的核心思想是:当系统在等待用户审批时,不要空等——先预测用户可能输入的内容,提前执行。
在 src/services/PromptSuggestion/speculation.ts 中,推测执行的架构分为三层:
- Prompt Suggestion:预测用户下一条输入
- Speculative Execution:基于预测的输入,启动一个 Forked Agent 提前执行
- Acceptance/Rejection:如果用户实际输入与预测一致,直接采用结果;否则丢弃
10.3.2 安全边界
推测执行最大的风险在于:预测可能是错误的,提前执行的操作可能不是用户想要的。 源码中对此有严格的安全控制。
首先,工具被分为三类:
const WRITE_TOOLS = new Set(['Edit', 'Write', 'NotebookEdit'])
const SAFE_READ_ONLY_TOOLS = new Set([
'Read', 'Glob', 'Grep', 'ToolSearch', 'LSP', 'TaskGet', 'TaskList',
])只读工具(SAFE_READ_ONLY_TOOLS)可以直接执行。写入工具(WRITE_TOOLS)只有在用户已经设置了 acceptEdits 或 bypassPermissions 模式时才允许,否则推测执行会在此处暂停。对于 Bash 命令,只有通过只读验证(checkReadOnlyConstraints)的命令才能在推测中执行——任何可能有副作用的 Shell 命令都会导致推测停止。
其次,所有写操作都发生在 Overlay 目录 中:
function getOverlayPath(id: string): string {
return join(getClaudeTempDir(), 'speculation', String(process.pid), id)
}这是一种类似 Copy-on-Write 的隔离策略。写入工具的文件路径会被重写到临时的 overlay 目录,读取工具在读取已修改的文件时也会被重定向到 overlay。只有当用户确认采纳推测结果时,overlay 中的文件才会被拷贝回主工作区:
async function copyOverlayToMain(overlayPath, writtenPaths, cwd) {
for (const rel of writtenPaths) {
const src = join(overlayPath, rel)
const dest = join(cwd, rel)
await mkdir(dirname(dest), { recursive: true })
await copyFile(src, dest)
}
}如果推测被中止——用户输入了不同的内容,或者推测过程中遇到了无法自动处理的操作——overlay 目录会被直接删除,不留痕迹。
10.3.3 流水线化的推测
更进一步,当一次推测成功完成后,系统会立即启动"下一轮"推测——预测用户在看到推测结果后的下一条输入。这就是 generatePipelinedSuggestion 函数的工作:
// Pipeline: generate the next suggestion while we wait for the user to accept
void generatePipelinedSuggestion(
contextRef.current,
suggestionText,
speculatedMessages,
setAppState,
abortController,
)这种流水线化设计意味着,当用户连续接受多个建议时,每一次都几乎是即时的——Agent 已经提前把活干完了。
10.3.4 推测执行的上限
为了防止推测失控,系统设置了硬性限制:
const MAX_SPECULATION_TURNS = 20
const MAX_SPECULATION_MESSAGES = 100最多 20 个 Agent 回合或 100 条消息。超过这个限制,推测会被自动终止。
10.4 Auto Mode:让 AI 判断安全性
10.4.1 分类器架构
Auto Mode 是 Claude Code 权限系统中最"智能"的部分。它不再依赖静态规则或用户交互,而是让一个 AI 分类器(Classifier)来判断每个操作是否安全。
Auto Mode 的状态管理在 src/utils/permissions/autoModeState.ts 中,极其简洁:
let autoModeActive = false
let autoModeFlagCli = false
let autoModeCircuitBroken = false三个布尔变量:是否激活、是否通过 CLI 启用、是否被熔断。
当权限系统遇到一个需要 ask 用户的操作时,如果当前处于 auto 模式,它不会弹出审批弹窗,而是调用分类器(在 src/utils/permissions/permissions.ts 中):
if (
feature('TRANSCRIPT_CLASSIFIER') &&
(appState.toolPermissionContext.mode === 'auto' ||
(appState.toolPermissionContext.mode === 'plan' &&
(autoModeStateModule?.isAutoModeActive() ?? false)))
) {
// 调用 AI 分类器判断...
}注意一个细节:Plan Mode 下如果 Auto Mode 处于激活状态,分类器同样会介入。这意味着 Plan + Auto 的组合可以实现"自动审批读操作"的效果。
10.4.2 危险权限剥离
Auto Mode 引入了一个独特的安全机制:进入 Auto Mode 时,危险的权限规则会被临时剥离。
在 src/utils/permissions/permissionSetup.ts 中,isDangerousBashPermission 函数定义了哪些规则是危险的:
- 无限制的 Bash 允许规则(
Bash或Bash(*)) - 脚本解释器前缀规则(
python:*、node:*等) - 通配符匹配解释器的规则
这些规则在 default 模式下可能是合理的——用户明确知道自己在做什么。但在 auto 模式下,它们会绕过分类器的安全评估,所以必须暂时移除。
export function transitionPermissionMode(fromMode, toMode, context) {
if (toUsesClassifier && !fromUsesClassifier) {
autoModeStateModule?.setAutoModeActive(true)
context = stripDangerousPermissionsForAutoMode(context)
} else if (fromUsesClassifier && !toUsesClassifier) {
autoModeStateModule?.setAutoModeActive(false)
context = restoreDangerousPermissions(context)
}
}退出 Auto Mode 时,这些规则会被恢复(restoreDangerousPermissions)。整个过程对用户透明,但确保了分类器始终是 Auto Mode 下的最终仲裁者。
10.4.3 熔断器机制
Auto Mode 还内置了熔断器(Circuit Breaker):
export function isAutoModeGateEnabled(): boolean {
if (autoModeStateModule?.isAutoModeCircuitBroken() ?? false) return false
if (isAutoModeDisabledBySettings()) return false
if (!modelSupportsAutoMode(getMainLoopModel())) return false
return true
}三种情况会触发熔断:
- 服务端远程熔断:通过 GrowthBook 配置动态禁用
- 用户设置禁用:在 settings.json 中关闭
- 模型不支持:当前模型没有 Auto Mode 能力
熔断器触发后,即使用户尝试通过 Shift+Tab 切换到 Auto Mode 也会被阻止——canCycleToAuto 会返回 false,直接跳过 Auto Mode。
10.5 模式切换的状态机
所有模式切换都经过 transitionPermissionMode 这个核心函数。它本质上是一个状态机,负责处理每种转换的副作用:
┌────────────────────────────────────────────┐
│ transitionPermissionMode │
│ │
│ fromMode → toMode │
│ │
│ 1. handlePlanModeTransition (附件管理) │
│ 2. handleAutoModeTransition (分类器生命周期)│
│ 3. Plan exit → setHasExitedPlanMode │
│ 4. Auto enter → stripDangerousPermissions │
│ 5. Auto exit → restoreDangerousPermissions │
│ 6. Plan enter → prepareContextForPlanMode │
└────────────────────────────────────────────┘这种集中化的设计确保了无论通过哪种路径切换模式——Shift+Tab、SDK 控制消息、EnterPlanModeTool——都会触发完全相同的副作用序列。
10.6 小结:Agent 安全的哲学思考
Claude Code 的 Permission Mode 设计揭示了一个深层哲学:AI Agent 的破坏力远大于普通程序。
普通程序的行为是确定性的——同样的输入产生同样的输出。但 AI Agent 的行为是概率性的,一次幻觉(hallucination)就可能让它执行 rm -rf / 或者将敏感数据发送到公网。更危险的是,Agent 拥有完整的工具链——文件读写、Shell 执行、网络请求——它的破坏半径远远超过一个普通的 bug。
因此,Claude Code 采取了"纵深防御"的安全策略:
- 默认保守:
default模式下每个敏感操作都需要审批 - 渐进放开:从
acceptEdits到auto再到bypassPermissions,每一级都明确告知风险 - 智能守卫:Auto Mode 的分类器不是简单的黑白名单,而是理解上下文的 AI
- 安全网兜底:即使在最宽松的模式下,危险权限也会被剥离;熔断器可以远程关闭 Auto Mode
- 隔离执行:推测执行通过 Overlay 目录确保预测错误时不会污染工作区
这套设计最精妙之处在于:它不是在安全和效率之间做简单的折中,而是通过 Permission Mode 这个维度,让用户自己根据场景选择合适的平衡点。同一个 Agent,在不同的信任级别下展现完全不同的行为——这才是 Agent 安全的正确姿势。
下一章,我们将深入 Claude Code 的 Bash 安全沙箱,看看当 Agent 需要执行 Shell 命令时,系统如何在操作系统层面构建最后一道防线。